출처 : http://pages.cs.wisc.edu/~remzi/OSTEP/
Concurrency
thread란?
프로세스는 새로운 프로그램을 돌릴 때 추상화를 제공합니다. 하지만 이 방법을 통한 동시성에는 한계가 있습니다.
- 단일 프로세스가 다중 코어의 혜택을 받을 수 없습니다.
- 많은 협력적 프로세스로 구성된 프로그램의 쓰기에서 꽤 성가신 문제가 있습니다.
- 새로운 프로세스를 만드는 데 비용이 큽니다.
- 프로세스간의 통신에 오버헤드가 큽니다.
- 프로세스간 컨택스트 스위칭을 하는 데 비용이 큽니다.
그렇게 해서 등장한 방법이 쓰레드(Thread) 방법입니다. 이런 쓰레드는 아래와 같은 내용을 가집니다.
- 쓰레드 ID
- PC와 스택 포인터와 같은 레지스터들
- 스택
이러한 멀티 쓰레드 프로그램은 실행 위치가 적어도 하나가 존재하며, 다중 PCs(Program Counter)이며, 각각은 동일한 메모리 주소를 공유합니다. 그림으로 표현하면 아래와 같습니다. 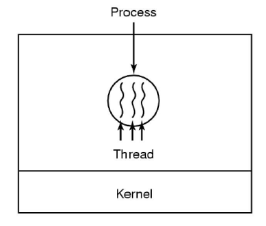 이런 쓰레드를 C언어에서 사용하시려면 아래와 같은 방식으로 사용할 수 있습니다.
이런 쓰레드를 C언어에서 사용하시려면 아래와 같은 방식으로 사용할 수 있습니다.
#include <stdio.h>
#include <pthread.h>
void *hello(void *arg){
printf("Hello World!!\n");
}
int main(){
pthread_t tid;
pthread_create(&tid, NULL, hello, NULL);
printf ("Hello from main thread\n");
}
이런 방식을 통해서 사용할 수 있습니다.
앞서 이야기 했듯이 쓰레드 사이에서 컨택스트 스위칭이 일어날 때 program counter와 레지스터의 집합이 저장 됩니다. 이는 다시 말해서 각각의 쓰레드가 상태를 저장하는 데 하나 또는 그 이상의 Thrad Control Blocks(TLBs)가 필요하다는 것을 알 수 있습니다.
이에 따라, 하나의 쓰레드(T1)에서 다른 하나의 쓰레드(T2)로 바뀔 때에는 아래와 같은 과정을 거치게 됩니다.
- T1의 레지스터 상태가 저장이 됩니다.
- T2의 레지스터 상태가 복구됩니다.
- 주소 공간은 동일하게 유지됩니다.
이러한 이유로 하나의 쓰레드는 하나의 스택을 가지게 됩니다. 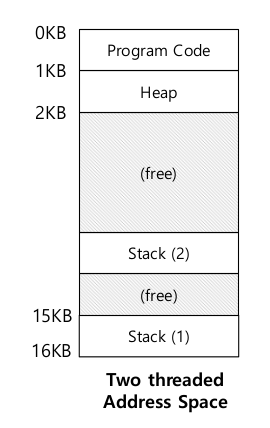
그렇다면 프로세스와 쓰레드의 차이점을 이제 알아보도록 하겠습니다.
| 프로세스 | 스레드 |
|---|---|
| 1 process N threads | 1 thread 1 process |
| 데이터의 공유에 비용이 비싸다 | 데이터의 공유에 비용이 싸다. |
| 어느 쓰레드가 실행될 지 들어가는 공간 | 스케쥴링의 단위 |
| 정적이다. | 동적이다. |
여기서 우리는 쓰레드를 사용하게 되면 다중 처리에 적합하다는 것을 다시 한 번 확인하게 되었습니다. 그렇다면 이런 쓰레드를 이용한 다중 처리, 멀티 쓰레딩(Multi-Threading)을 하면 어떤 점이 좋을까요?
- 동시성 프로그램을 만드는 비용이 적습니다.
- 프로그램을 더욱더 구조화 할 수 있습니다.
- 처리량(throughput)을 높일 수 있습니다.
- 반응성(reponsiveness)을 높일 수 있습니다.
- 자원 공유가 쉽습니다.
- 다중 코어 아키텍쳐를 활용할 수 있습니다. 이제 각 영역에서 어떻게 쓰레드가 동작하는 지 확인해보도록 하겠습니다.
Kernal-level Threads
커널 단계의 쓰레드는 OS에 의해서 관리되는 쓰레드 입니다. 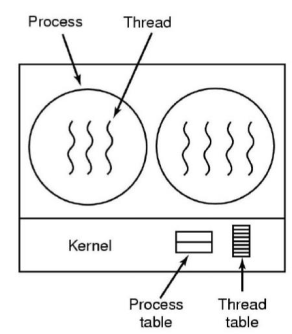 이런 커널 쓰레드는 아래와 같은 특징을 가집니다.
이런 커널 쓰레드는 아래와 같은 특징을 가집니다.
- OS는 쓰레드와 프로세스들을 관리합니다.
- 모든 쓰레드의 명령은 커널 안에서 실행됩니다.
- 쓰레드의 생성과 관리는 시스템 호출(System Call)을 필요로 합니다.
- OS는 모든 쓰레드의 작업 일정을 관리합니다.(scheduled)
- 프로세스를 생성하는 것에 비해 쓰레드의 생성이 훨씬 비용이 적급니다.
하지만 이런 커널 쓰레드 방식은 아래와 같은 한계을 가집니다.
- 프로세스 보단 적지만 시스템 전체로 봤을 때 여전히 비용이 큽니다.
- 쓰레드의 명령들이 모두 시스템 호출을 필요로 합니다.
- 각각의 쓰레드는 반드시 커널 상태를 유지해야 합니다. 그러므로 동시에 돌릴 수 있는 쓰레드의 수가 한정적입니다.
- 운영 체제는 반드시 늘어나는 쓰레드에 대한 확장성을 지녀야 합니다.
- 반드시 모든 프로그래머, 언어, 런타임 환경에서 보편적으로 동작해야만 합니다.
이제 커널 단계에서 관리되는 쓰레드와 다른 사용자 단계에서 관리되는 쓰레드를 알아보도록 하겠습니다.
User-level Threads
사용자 단계의 쓰레드는 사용자 프로그램에서 관리되는 것입니다. 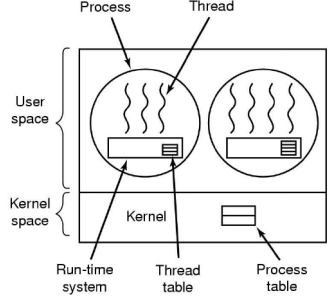 자세히 말하면 아래와 같은 특징을 가진다고 할 수 있습니다.
자세히 말하면 아래와 같은 특징을 가진다고 할 수 있습니다.
- 쓰레드들은 사용자 단계에서 수행됩니다.
- 쓰레드를 프로그램에 링킹된(linked) 라이브러리가 관리합니다.
- 쓰레드는 운영체제에는 보이지 않습니다.
- 모든 쓰레드의 동작은 프로시저의 호출을 통해 종료됩니다.
- 커널 단계의 쓰레드에 비해 10 ~ 100배 정도 빠르며 크기가 작습니다.
- 그리고 하나의 프로세스에 귀속되기 때문에 포터블(portable)한 특징을 지닙니다.
- 응용 프로그램이 필요로 하는 많큼 제작 가능합니다.
이런 사용자 단계도 커널 단계와 동일하게 완벽하다고 볼 수 없고 어느 정도의 한계를 지닙니다.
- 일반적으로, 비선점적 스케쥴링에 의존합니다. 만약 선점적 스케쥴링의 경우 Unix SIgnals를 이용해서 에뮬레이팅을 할 수 있습니다.
- 운영체제는 사용자 단계의 쓰레드라 인지하지 못하고 올바르지 않은 선택을 할 수 있습니다. 아래와 같은 경우가 발생할 수 있습니다.
- 유휴(idle) 상태의 쓰레드만 모인 프로세스를 스케쥴링을 할 수 있습니다.
- 하나의 쓰레드가 시작한 I/O에 의해 모든 프로세스가 멈출 수(blocking) 있습니다.
- 락을 가지고 있는 쓰레드에 의해 프로세스가 스케쥴링이 안 될 수 있습니다.
- 모든 blocking system calls는 커널의 non-blocking calls를 통해 에뮬레이트(emulated) 될 수 있습니다. 즉, 이 말은 커널과 쓰레드 관리자 사이에 협력이 필요함을 의미합니다.
- 다중 코어 CPU들을 사용할 수 없습니다.
Race Condition
쓰레드에는 Race Condition이라고 있는 데, 이는 공유 자원을 어떤 쓰레드가 먼저 읽었는가?와 같은 접근 순서, 타이밍 같은 것이 결과에 영향을 끼치는 상태를 의미합니다. 즉, 이를 다시말하면 비결정적(indeterminate)이라고 합니다. 
Critical Section
공유 변수에 접근하는 어느 코드(이를 테면 함수)의 경우 하나 이상의 쓰레드가 동시에 접근해서 안된는 공간을 의미합니다. 이런 공간에 여러 개의 쓰레드가 접근을 하여 실행을 하면 결과는 경쟁 상태(Race Condition)으로 결정됩니다. 따라서 임계 영역들(Critical Sections)을 원자적으로(atomicity) 만들 필요성이 있습니다. 이는 즉 구역을 상호 배제(Mutual Exclusion)로 만들어야 함을 의미합니다.
여기서 상호 배제는 하나의 쓰레드가 임계 영역에서 실행이 되면 다른 것들은 작업을 하는 것을 방지하는 것을 의미합니다. 이를 위해서 lock이라는 것을 사용합니다. 이는 다음 시간에 확인을 해보도록 하겠습니다.
Example
C를 기준으로 thread를 설명하도록 하겠습니다. 어떻게 쓰레드들을 생성하고 제어할까요?
#include<pthread.h>
int pthread_create( pthread_t* thread,
const pthread_attr_t* attr,
void* (*start_routine)(void*),
void* arg);
여기서 각각이 의미하는 바는 아래와 같습니다.
| 항 목 | 내 용 |
|---|---|
| thread | 이것에 의해 만들어지는 쓰레드의 대상을 위해 사용되는 부분입니다. |
| attr | 이 쓰레드가 가지는 특정 구성 요소를 가지는 데 사용되는 요소입니다. |
| start_routine | 이 쓰레드가 돌리는 함수를 할당하는 부분입니다. |
| arg | start_routine에 들어가는 함수에 할당할 매개 변수 값을 지정해주도록 합니다. |
이를 활용해서 소스코드를 작성을 하면 아래와 같이 작성이 됩니다.
#include <pthread.h>
typedef struct __myarg_t {
int a;
int b;
} myarg_t;
void *mythread(void *arg) {
myarg_t *m = (myarg_t *) arg;
printf("%d %d\n", m->a, m->b);
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p;
int rc;
myarg_t args;
args.a = 10;
args.b = 20;
rc = pthread_create(&p, NULL, mythread, &args);
...
}
하지만 이대로만 제작을 하면 정상적으로 돌아감을 보장할 수 없습니다. 왜냐하면 main도 하나의 쓰레드이므로 실행하고자 하는 쓰레도에 비해 main이 먼저 끝나는 문제점이 발생할 수 있습니다.
이를 해결하기 위해서는 아래와 같은 명령어를 사용하도록 해야 합니다. int pthread_join(pthread_t thread, void **value_ptr); 여기서 thread는 기다리기를 원하는 쓰레드를 보관하는 매개 변수이고, value_ptr은 반환되는 값의 포인터를 의미합니다. 이러한 함수를 사용하게 되면 아까 실행한 쓰레드가 종료될 때까지 main은 종료되지 않게 됩니다.
결과적으로, 돌아가는 코드를 짜면 아래와 같이 됩니다.
#include <stdio.h>
#include <pthread.h>
#include <assert.h>
#include <stdlib.h>
typedef struct __myarg_t{
int a;
int b;
} myarg_t;
typedef struct __myret{
int x;
int y;
} myret_t;
void *mythread(void *arg){
myarg_t *m = (myarg_t *) arg;
printf("%d %d\n", m->a, m->b);
myret_t *r = malloc(sizeof(myret_t));
// myret_t r; //
r->x = 1;
r->y = 2;
return (void *)r;
}
int main(int argc, char *argv[]){
int rc;
pthread_t p;
myret_t *m;
myarg_t args;
args.a = 10;
args.b = 20;
pthread_create(&p, NULL, mythread, &args);
pthread_join(p, (void **) &m);
printf("returned %d %d\n", m->x, m->y);
return 0;
}