출처 : http://pages.cs.wisc.edu/~remzi/OSTEP/
이 게시글은 2018년에 작성한 내용을 복구한 것으로 원문은 개정되었을 수 있으니 참고 바랍니다.
Scheduling
Introduction
시스템은 여러 개의 프로세스가 올라가서 돌아가게 됩니다. 그러므로 정책을 잘 활용을 해서 프로세스의 순서를 정해 줄 필요가 있는 데, 이를 보고 Scheduling(이하 스케쥴링)이라고 합니다. 일반적으로 스케쥴링의 접근 방법은 2가지로 나뉠 수 있습니다.
-
Non-preemptive scheduling(비선점적 스케쥴링)
-
스케쥴러가 프로세스를 강제로 뭔가를 할 수 있는 방법은 없고 CPU만이 그 권한이 있습니다.
-
프로세스는 협력적이여야 합니다.
-
-
Preemtive scheduling(선점적 스케쥴링)
-
대부분의 현대의 스케쥴링 방식이 해당됩니다.
-
대표적인 예로 Time sharing 방식이 있습니다.
-
스케쥴러는 Process를 Interrup를 하고 Context Switch를 강제적으로 수행합니다.
-
그리고 들어가기 전에 용어를 확인을 해보도록 하겠습니다.
| 항 목 | 내 용 |
|---|---|
| Workload | 작업 상세의 집합입니다. |
| Scheduler | 다음 작업을 무엇을 할까에 대한 Logic입니다. |
| Metric | 성능의 평가 기준을 의미합니다. |
이 용어를 바탕으로 이제 내용을 확인해보도록 하겠습니다.
스케쥴링의 Metric으로는 Turnaround Time과 Fairness로 나뉩니다. 먼저 전자에 관해서 알아보도록 하겠습니다 Turnaround Time은 작업이 종료되는 시간에서 작업이 도착한 시간을 뺀 값을 의미합니다. 이를 수식화하면 아래와 같이 됩니다.
\(T_{turnaround} = T_{completion} - T_{arrival}\)
Fairness 방법은 얼마나 프로세스가 공평하게 CPU를 할당을 받는가와 관련이 있습니다. 결과적으로, Turnaround Time과 Fairness는 모순적인 관계이므로 둘을 조화롭게 만들 필요가 있습니다.
위의 목적을 달성하기 위해 가장 처음 나온 방식은 First In, First Out(이하 FIFO)가 있습니다. 이 방법은 비선점적 방식으로 매우 쉽고 간단하게 구현이 가능합니다. 이 방식에 따르면 모든 작업들은 동등하게 처리되기 때문에 starvation이 발생 할 수가 없습니다. 예시를 들어 설명을 하도록 하겠습니다. 여기서 괄호 내용은 (도착시간, 실행시간)으로 구성됩니다. 그리고 근사의 차이로 A, B, C가 차례로 들어왔다고 가정하겠습니다.
\(A= (0, 10)\) \(B=(0,10)\) \(C=(0,10)\)
이런 경우에 A, B, C순으로 들어왔으므로 처음 들어온 A는 실제로 도착 0, 종료 10 ; B는 도착 0, 종료 20 ; C는 도착 0, 종료 30이 됩니다. 결과적으로 평균 Turnaround Time을 계산을 하면 아래와 같이 됩니다.
\(Average\) \(turnaround\) \(time\) \(=\) \(\dfrac{10 + 20 + 30}{3} = 20sec\)
각각 10, 20, 30은 A의 도착에서 끝, B의 도착에서 끝, C의 도착에서 끝에 해당합니다. 그렇다면 이런 FIFO가 대단한 것인가라고 볼 수 있을까요? 그렇지만은 않습니다. 왜냐하면 Convoy Effect가 발생할 수 있기 때문입니다. 예를 들어, 이번에는 A, B, C가 아래를 따른다고 하겠습니다.
\(A=(0,100)\) \(B = (0, 10)\) \(C =(0, 10)\)
이 경우에 A, B, C순으로 근사하게 들어온 경우 FIFO에 따르면 아래와 같이 됩니다.
\(Average\) \(turnaround\) \(time\) \(=\) \(\dfrac{100 + 110 + 120}{3} = 110sec\)
만약 B, C, A순으로 근사하게 들어온 경우 계산을 해보도록 하겠습니다.
\(Average\) \(turnaround\) \(time\) \(=\) \(\dfrac{10 + 20 + 120}{3} = 50sec\)
결과적으로, A가 언제 들어오느냐?가 성능을 크게 좌우한다는 것을 알 수 있습니다. 이는 상당히 비효율적이라고 할 수 있습니다. 따라서 이를 해결하기 위해서 새로운 방법이 등장하게 됩니다.
Shortest Job First(이하 SJF)는 FIFO와 동일하게 비선점적 방식입니다. 이 방식은 시스템에 도착하는 시간이 동일하다면 가장 짧은 것을 먼저 실행을 시킨다는 이념으로 동작을 합니다. 그렇게 하면 위에서 언급한
\(A=(0,100)\) \(B = (0, 10)\) \(C =(0, 10)\)
에서 A, B, C로 들어와도 B, C, A로 변경이 되게 됩니다. 하지만 이 방식도 명백한 문제점을 가지고 있습니다. 앞에서 이야기 했듯이 근사하게 도착을 한다면 시스템에서 처리를 할 수 있지만 느리게 도착을 하는 경우 문제가 발생하게 됩니다. 아래와 같은 경우를 보도록 하겠습니다.
\(A=(0,100)\) \(B = (10, 10)\) \(C =(10, 10)\)
SJF를 적용하여 Average turnaround Time을 구해보도록 하겠습니다.
\(Average\) \(turnaround\) \(time\) \(=\) \(\dfrac{100 + (110-10) + (120-10)}{3} = 103.33sec\)
조금이라도 늦는 순간 A가 또다시 Convoy Effect를 발생 시키게 됩니다. 따라서 이것을 해결할 필요가 있게 됩니다. 이를 해결 하기 위해 Shortest Time-to-Completion First(이하 STCF)가 생기게 됩니다. 이 방식은 선점적 방식으로 새로운 작업이 들어왔는 데 이 작업이 기존의 작업보다 더 짧은 수행 시간을 가지면 이 작업으로 변경을 하는 방식입니다. 이에 따르면, 아래와 같이 작업이 수행이 됩니다.

\(Average\) \(turnaround\) \(time\) \(=\) \(\dfrac{(120-0) + (20-10) + (30-10)}{3} = 50sec\)
이전의 방식보다 장족인 발전을 하게되었습니다. 하지만 이 방식에 치명적인 문제가 있습니다. 앞서 언급한 FIFO같은 경우 Starvation이 발생하지 않습니다. 어떤 내용이 들어오면 그 내용이 무엇이든 간에 언젠가는 종료가 되기 때문입니다. 하지만 STCF의 경우 예를 들어, 수행 시간 100짜리 1개가 있고 수행 시간 10짜리가 무한히 계속 들어온다면 Starvation이 발생을 하게 됩니다. A는 전혀 작업을 수행할 수 없게 됩니다. 하지만 그럼에도 불구하고 Turnaround time에서는 좋은 성능을 보여주고 있습니다. 따라서 새로운 성능 측정 방식의 필요성이 나타나게 되었습니다.
그렇게 나온 새로운 측정 방법은 Response Time을 측정하는 방법입니다. 이 방법은 작업이 도착해서 처음으로 실행되는 때의 간격을 바탕으로 측정을 하는 방식입니다. 이 방식은 아래와 같습니다.
\(T_{response} = T_{firstrun} - T_{arrival}\)
이 방식을 토대로 STCF를 계산을 하면 썩 좋은 성능을 보여주진 못합니다. 이에 관해서는 뒤에서 알아보도록 하겠습니다. 따라서 이런 Response Time을 개선하기 위해 새로운 방법이 요구되었고, Round Robin(이하 RR)이 등장하게 되었습니다. RR은 시분할 스케쥴링(Time slicing Scheduling) 방법으로 순회 FIFO 큐(Circular FIFO Queue)로 작업이 처리됩니다. 이 방식은 주의해야 할 것이 Time Slice의 크기는 부팅이 시작되고 일정 시간 반복되는 Timer Interrupt보단 그 값이 2배 이상 이어야 합니다. 이 말은 어떤 컴퓨터의 Timer Interrupt가 2ms라고 가정을 하면 Timer Slice는 4ms 이상이 무조건 되어야 함을 의미 합니다. 결과적으로 이런 RR은 선점적인 방식이면서 STCF의 Starvation의 문제를 해결한 방식입니다. 예제를 통해서 RR과 STCF를 비교해보도록 하겠습니다.
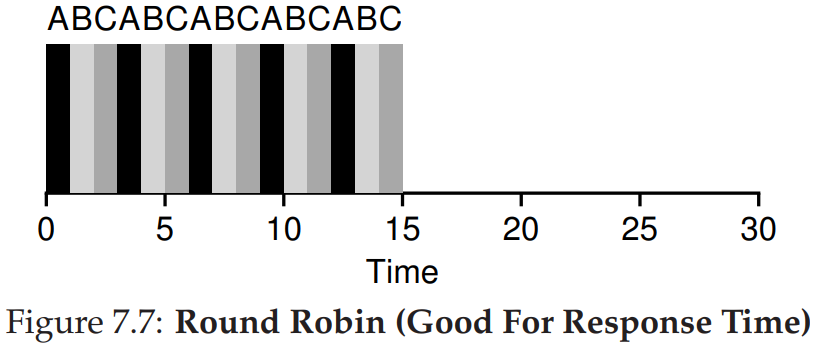
여기서 RR이 Turnaround Time은 낮을 지 몰라도 매우 좋은 Response Time을 가짐은 알 수 있습니다. 하지만 이런 RR도 만능은 아닙니다. 이 RR은 무엇보다 Time Slice의 크기가 성능에 크게 좌우를 하게 됩니다. 너무 작은 Time Slice는 Response Time은 획기적으로 줄일 수 있지만, Context Switching을 하면서 벌어지는 성능 저하를 무시할 순 없습니다. 그리고 너무 큰 Time Slice는 Context Switching의 비용은 낮추지만, 낮은 반응 시간으로 오히려 STCF보다 안 좋은 결과를 야기할 수 있습니다. 결과적으로, RR도 둘 사이를 적절하게 하는 것이 중요하다는 것을 알 수 있습니다. 잠시 여담으로 RR의 Time Slice가 \(\infty\)이면 FIFO랑 동일한 기능을 하게 됩니다.
그리고 이번 단원을 마치기 전에 협력적 I/O라고 있는 데 이는 CPU가 노는 것을 보지 못한 사용자들이 I/O가 프로세스의 작업을 처리 중이라고 CPU에게 말해서 CPU가 일을 할 수 있도록 만드는 것을 말합니다.
The Multi-Level Feedback Queue
기존의 방식에는 프로세스의 우선순위를 정할 수 없었습니다. 또한 SJF, STCF, RR은 단점이 존재하게 되었습니다. 이 모든 것을 해결하기 위해 이 방법이 나타나게 되었습니다. MLFQ는 구분되는 여러 큐를 가집니다. 그리고 각각의 큐는 서로 다른 우선 순위를 가집니다. 그리고 작업 순위가 높은 큐를 먼저 실행을 하게 됩니다. 그리고 각 같은 Queue에 있는 각 작업들은 RR을 사용하여 수행하도록 합니다. 이런 규칙 1, 2에 해당하는 내용을 제외하고 규칙은 총 5개가 있습니다.
-
Rule 1 : IF priority(A) > priority(B) THEN A runs (B doesn’t)
-
Rule 2 : IF priority(A) = priority(B) THEN A & B run in RR
-
Rule 3 : 시스템에 작업이 들어갔을 때, 높은 우선 순위로 설정이 됩니다.
-
Rule 4
-
a : 만약 작업이 모든 점유 시간(Time-Slice)을 실행에 다 소모 했을 경우, 그것의 우선순위는 떨어집니다.
-
b : 만약 작업이 시간을 사용하기 전에 CPU에서 포기되었다면, 그것은 동일한 우선 순위를 가집니다.
-
-
Rule 5 : S 주기가 지나면 모든 작업을 가장 높은 큐로 이동을 하도록 합니다.
그리고 MLFQ는 짧은 실행시간을 가지고 빠른 반응 시간이 필요로 하는 Interactive한 작업에 대해서는 높은 우선순위를 유지시키도록 합니다. 그리고 오랜 기간 CPU에서 사용되며 반응 시간과 상관 관계가 적은 CPU-Intensive한 작업에 대해서는 우선순위를 낮추도록 합니다. 하지만 이런 방식만 이용하면 MLFQ는 치명적인 문제가 생기게 됩니다.
-
Starvation : Interactive 작업이 너무 많아서 Intensive한 작업이 전혀 실행이 되지 않을 수 있습니다.
-
Game the Scheduler : 작업이 99% 수행을 할 때 마다 I/O를 요청해서 스케쥴러를 속여 CPU를 점유합니다.
이를 해결하기 위해서 3가지 방법이 나타나게 되었습니다.
-
Priority Boost : 주기적으로 작업의 우선순위를 올려주도록 합니다.
-
Better Accounting
점유 시간(Time-Slice)을 전체 시간을 기준이 아니라 해당 우선 순위에서 수행한 시간을 기준으로 합니다.
-
Tuning MLFQ : 높은 우선 순위는 점유 시간을 줄이고 낮은 우선 순위는 높입니다.