Routing
라우팅(Routing)은 IP 레이어(레이어 3)의 라우터를 위해 포워딩 테이블(Forwarding Table)을 만드는 방법입니다. 이러한 라우팅의 방법에는 2가지가 있습니다.
- 거리 벡터(Distance-Vector): 분산 벨만 포드(Distributed Bellman-Ford)
- 링크 상태(Link-State): 다익스트라(Dijkstra)
여기서 거리 벡터 같은 경우는 무한대 계산 문제가 있는 데 이는 뒤에서 알아보도록 하겠습니다. 그리고 이런 라우팅은 계층적으로 이루어지게 됩니다. 먼저 포워딩이란 것은 출력 포트를 목적지 주소와 포워딩 테이블에 따라서 고르는 것을 의미합니다. 그리고 라우팅은 포워딩 테이블을 만드는 과정이라고 할 수 있습니다. 이러한 라우팅은 그래프 문제를 푸는 것과 같습니다. 여기서 문제는 두 개의 정점 사이에 가장 낮은 비용을 찾는 것이 될 수 있습니다.
2개를 표로 정리하면 아래와 같은 표를 만들 수 있습니다.
| 항목 | 거리 벡터 | 링크 상태 |
|---|---|---|
| 알고리즘 | 분산 벨만 포드 | 다익스트라 |
| 교환되는 정보 | 거리 벡터 | 링크 상태 |
| 교환 대상 | 이웃 라우터 | 네트워크 상 모든 라우터 |
| 표준 프로토콜 | RIP (Routing Information Protocol) | OSDF (Open Shortest Path First) |
인터넷 개발 초창기에 먼저 적용된 것은 거리 벡터 방식입니다. 따라서 최초의 라우팅 프로토콜(Protocol)은 RIP라고 할 수 있습니다. 이후에 링크 상태가 나오면서 OSPF 프로토콜이 나왔다고 생각하시면 됩니다.
Distance Vector
거리 벡터(Distance Vector)는 모든 가능한 목적지에 대해서 그 거리와 다음 홉(next-hop)을 담도록 합니다. 그리고 이러한 거리 벡터에 대해서 분산 벨만 포드 알고리즘을 적용하도록 합니다. 그리고 링크 상태는 정점의 링크에 연결된 상태와 링크의 비용이 들어가게 됩니다. 아래와 같은 그래프에 대해서 거리 벡터는 왼쪽과 같이 링크 상태는 오른쪽과 같이 됩니다.
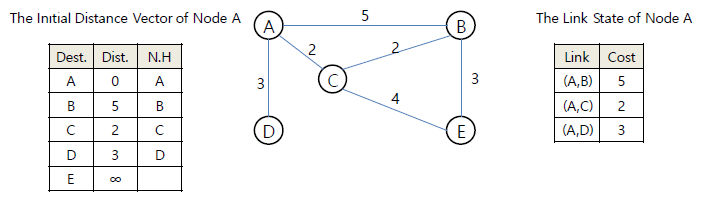
거리 벡터의 경우 테이블의 열 데이터로 목적지, 거리/비용, 다음 홉을 가지게 됩니다. 여기서 다음 홉이라는 것은 가장 짧은 거리에서 다음 목적지를 의미합니다. 예를 들어, 부산의 포워딩 테이블의 행 중에 서울, 700, 진주라는 것은 서울을 가장 적은 비용은 700이며, 이 짧은 거리로 가는 경우 처음으로 들러야 할 곳은 진주임을 이야기합니다.
Link-State
링크 상태(Link-State)의 경우 모든 라우터가 본인의 링크 상태를 보내서 다들 뭐가 어디로 가는지 테이블을 만들도록 합니다. 이 방식은 길 찾는 거로 한다면 지도를 애초에 가지고 시작하는 단계라고 생각하면 됩니다. 그렇게 만들어진 데이터에 따라 다익스트라 알고리즘을 적용하면 최단거리를 구할 수 있습니다. 아래는 다익스트라 알고리즘의 의사 코드(Pseudo Code)입니다.
DIJKSTRA(G,w,s) <- w는 비용, s는 시작점을 의미합니다.
INITIALIZE-SINGLE-SOURCE(G, s)
S = φ <- 들른 곳을 의미합니다.
Q = G.V
while Q ≠ φ
u = EXTRACT_MIN(Q)
S = S ∪ {u}
for 각 정점 v ∈ G.Adj[u]
RELAX(u, v, w) <- v의 비용을 작게 만들면 갱신됩니다.
Count-to-Infinity Problem in Distance Vector
거리 벡터에는 라우팅 루프(loop)를 돌 수 있는 큰 문제가 있습니다. 이 문제는 네트워크가 죽을 때에 발생하게 됩니다. 예를 들어, A-B-C와 같이 연결되고 각 간선이 1인 상황에서 아래와 같은 과정이 발생할 수 있습니다.
- A와 B가 끊어지게 됩니다.
- 동시에 B가 테이블에서 갈 수 없는 A를 무한대 길이로 수정합니다.
- 그리고 약간의 시간이 지나고 C가 라우팅 테이블을 B에 줍니다.
- 여기서 C는 A, B 사이에 무슨 일이 벌어지는지 모르고 알고 있는 B가 일전에 말한 ‘너는 A까지 2번에 갈 수 있어’였습니다. 그래서 C는 그냥 그대로 줍니다.
- 그러고 B는 C가 A에 2번 만에 갈 수 있는 라우팅 테이블을 받게 되고, B는 C로 가면 된다 생각하고, A를 가려면 C를 거쳐서 나는 3번 만에 갈 수 있다고 수정합니다.
- 또 시간이 지나 B는 C에게 자신의 테이블을 주고, C는 B가 3번 만에 간다는 것만 믿고 A를 가려면 B를 거치고 자신은 4번 만에 간다고 수정합니다.
이렇게 5, 6이 반복되면 결국에 B, C는 서로에게 무한대로 가게 되고, 완벽한 루프가 만들어지게 됩니다. 따라서, 거리 벡터를 사용할 때는 이런 것을 유의하고 제작을 해야 합니다.
Hierarchical Routing
계층형 라우팅은 지역에 따라 집합이 만들어지는 데 이를 보고 AS(Autonomous System)이라고 합니다.
그리고 같은 AS에 존재하는 라우터들은 같은 라우팅 프로토콜(protocol)을 사용합니다. 이를 보고, 인트라(intra)-AS 라우팅 프로토콜 다른 이름으로는 내부 게이트웨이 프로토콜(IGP, Interior Gateway Protocol)이라고 합니다. 서로 다른 AS에 있는 라우터는 서로 다른 인트라-AS 라우팅 프로토콜이 존재 할 수 있습니다. 서로 다른 AS 사이에서는 서로의 인트라-AS 라우팅 프로토콜에 관해서 관여할 수 없습니다. 가장 많이 쓰이는 인트라-AS 라우팅 프로토콜로는 RIP, OSPF, IGRP가 있습니다. 앞 2개는 위의 거리 벡터와 링크 상태에서 언급한 프로토콜이고, IGRP는 위의 IGP에 R(Routing)이 들어간 것으로 CISCO에 소유권이 있습니다.
여기서 서로 다른 AS를 연결하는 라우팅 프로토콜을 인터(inter)-AS 라우팅 프로토콜이라고 합니다. 이는 AS와 AS 사이에 라우팅하는 규칙이 있습니다. 이러한 인터-AS 라우팅 프로토콜로 유명한 것은 경계 게이트웨이 프로토콜(BGP, Border Gateway Protocol)입니다. 이는 사실상 표준으로 잡은 프로토콜로 하는 일로는 아래와 같습니다.
- 이웃 AS에 갈 수 있는 서브넷의 정보를 가지고 있습니다.
- AS 내부의 모든 라우터의 정보를 가지고 있습니다.
- 정보와 정책을 기반으로 하여 좋은 서브넷 라우터를 선택하도록 합니다.
사실 이 프로토콜은 존재하는 인터넷에 대해 서브넷이 “내가 여기 있다!”라고 광고하게 허락하는 것으로 생각하면 됩니다.
이 둘을 비교하면 아래와 같이 정리할 수 있습니다.
| 항목 | 인트라-AS | 인터-AS |
|---|---|---|
| 정책 | 관리자는 라우팅 된 트래픽의 제어권을 넘겨받아서 처리합니다. | 단일 관리자에 의해 동작하므로 정책은 없습니다. |
| 성능 | 성능에 초점을 둡니다. | 성능보다는 정책에 제어됩니다. |
성능을 보면 내부(intra-)는 성능이 중요한 데 외부(inter-)는 정책이 중요하다고 합니다. 왜냐하면, 내부에서는 얼마나 빨리 일을 처리하는 게 중요하지만, 외부는 사람으로 치면 출입국 심사와 같은 일이 더욱 중요하기 때문입니다. 이 방법은 결과적으로 계층적인 라우팅 방식이기 때문에 테이블의 크기를 아낄 수 있으며, 트래픽의 증가를 막을 수 있어 확장성을 보장해주게 됩니다.