출처 : http://pages.cs.wisc.edu/~remzi/OSTEP/
이 게시글은 2018년에 작성한 내용을 복구한 것으로 원문은 개정되었을 수 있으니 참고 바랍니다.
Memory
Virtual Memory
메모리 가상화는 각 프로세스로 하여금 각각의 프로세스가 그들의 전용 메모리가 있도록 착각하게 만드는 것이 목적인 방법 입니다. 이런 메모리 가상화의 목적은 아래와 같습니다.
-
Transparency : 메모리를 공유하는 문제를 생각할 필요 없게 만드는 것을 의미합니다.
-
Efficiency : 공간과 시간을 최소화해야 합니다. 예를 들어, Fragmentation의 문제를 최소화 해야 합니다.
-
Protection : 다른 프로세스의 주소공간을 침범하는 것을 막아야 합니다.
과거의 OS 시스템은 하나의 메모리에 하나의 프로세스만 올릴 수 있었습니다. 이 방법은 상당히 활용성과 효율성이 좋지 못합니다. 그래서 Muliporgramming and Time Sharing방식이 나오게 되었습니다. 이 방식은 여러 프로세스를 메모리에 올릴 수 있습니다. 한 프로세스를 잠시 동안 실행을 하고 다른 프로세스로 넘어가는 방식입니다. 이렇게 하여 활용성과 효율성을 높일 수 있습니다. 하지만 이 방법은 다른 프로세스에 의해 잘못된 메모리의 접근이 발생하는 보안 문제가 생길 수 있습니다.
이를 해결하기 위해 각각의 프로세스에 고유의 메모리를 주는 Address Space 방식을 만들었습니다. 이는 메모리를 Prgram Code 부분과 Heap영역과 Stack 영역으로 나누는 방식입니다.

현대의 대부분의 시스템이 가지는 방식입니다. 여기서 각각의 부분은 아래와 같이 정의됩니다.
-
Code : 실행해야하는 명령어들이 들어가는 위치입니다.
-
Heap : 동적으로 할당된 메모리들하고 관련된 위치입니다.
-
Stack : 반환하는 주소와 값을 저장하는 위치입니다.
이 방식은 아래와 같은 과정을 통해서 물리적 메모리로 변환이 되게 됩니다.
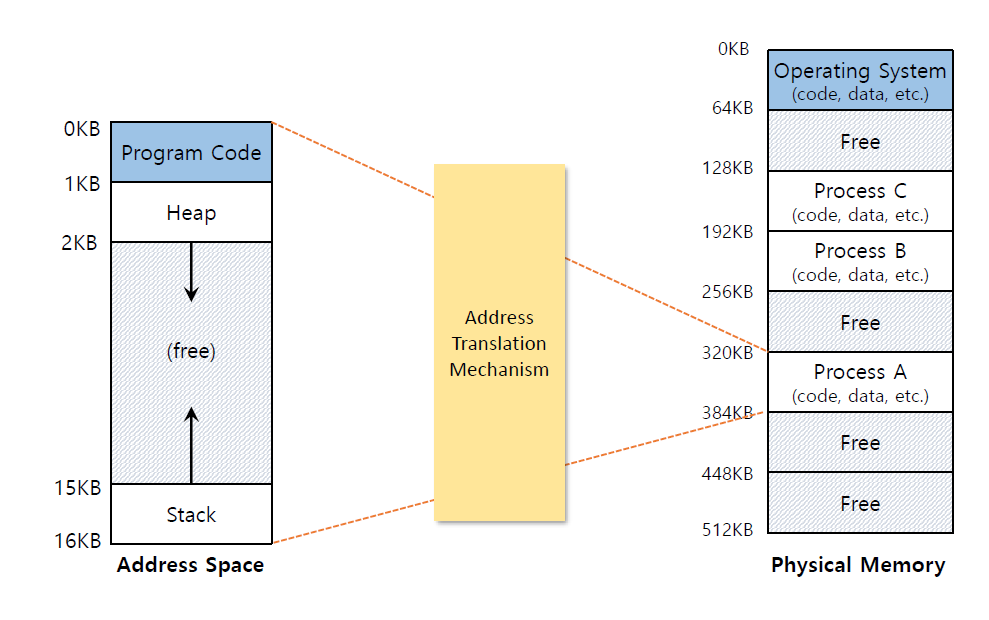
결과적으로 각각의 프로세스는 고유의 메모리를 가지고 해당 가상 주소를 바탕으로 동작을 하게 됩니다.
Address Translation
앞에서 우리는 메모리 가상화를 효율적으로 제어하기 위해 하드웨어의 지원이 필요하게 됩니다. 하드웨어는 가상 주소를 물리 주소로 변경하게 되고, OS는 어떤 위치가 사용 중인지 아닌지를 알고 있을 필요가 있습니다. 이런 주소의 변환을 Relocation Address Space라고 합니다. 이런 Relocation 방식으로 Static 방식과 Dynamic 방식이 있습니다. Static은 소프트웨어로 Relocation을 구현하는 방식이고, Dynamic은 Memory Management Unit(MMU)를 사용해서 Relocation을 구현하는 방식입니다. 정리하면 아래와 같습니다.
| Static Relocation | Dynamic Relocation | |
|---|---|---|
| 장 점 | 별다른 하드웨어적 구현이 필요로 하지 않는다. | 보안성이 높습니다. |
| 단 점 | 보안 및 메모리 위치 변경 불가의 문제가 있습니다. | 별도의 하드웨어를 필요로 하게 됩니다. |
그리고 특히 Static Relocation의 메모리 위치 변경의 불가로 인해 새로운 프로세스의 할당에 External Fragmentation이 발생할 수 있습니다. 이런 Static Relocation 보단 Dynamic Allocation에 관해서 좀 더 알아보도록 하겠습니다. Dynamic Relocation은 먼저 base register의 값을 바탕으로 값을 설정합니다. 그 공식은 아래와 같습니다.
\(\)physical:address = virtual:address + base\(\)
로 구성되며, 모든 가상 주소는 경계 값(bound)보다 크거나 음수가 될 수 없습니다.
\(0 \leq virtual\:address \leq bounds\)
이 방법을 사용하기 위해서는 OS가 빈 공간에 대해서 가지고 있을 필요가 있습니다. 이를 위해 OS는 빈 공간에 관련된 Queue를 가지고 있습니다.
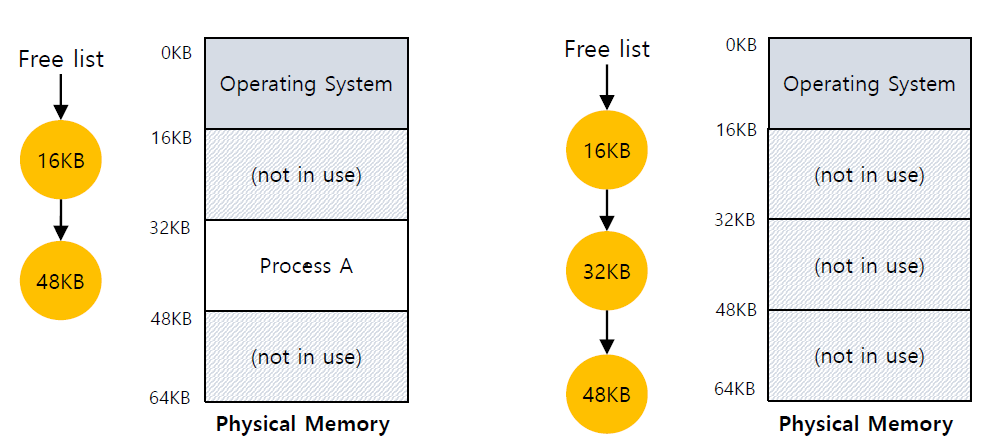
또한 Process의 PCB에는 Base와 Bounds를 저장을 해야하고, 이 내용을 바탕으로 OS는 메모리 관리를 해야 합니다.
Segmentation
Base 및 Bound 접근법은 중간에 빈 공간이 생기게 되어 효율적이지 않습니다. Segmentation을 사용하는 방법이 있습니다. 이 방법은 주소 공간을 논리적 Segment로 나누는 것을 의미합니다. 각각의 Segment는 각자 Base와 Bounds를 가지는 독립적인 것입니다. 이는 아래와 같은 모양으로 나타나게 됩니다.
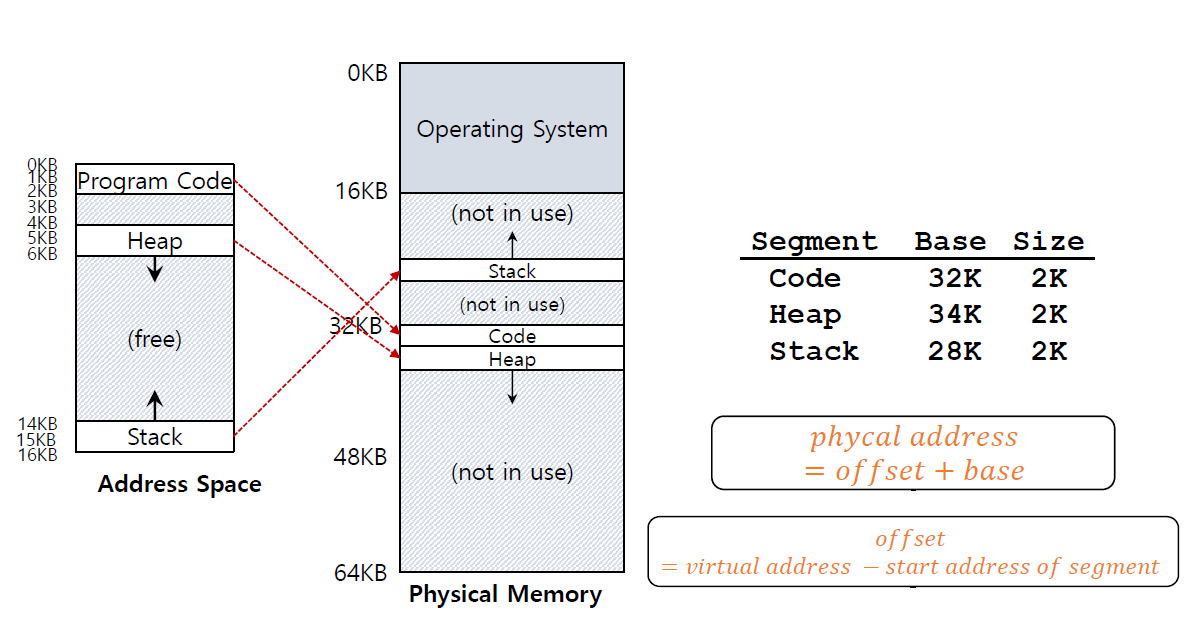
이런 식으로 하여 계산을 하면 Virtual Address가 100인 곳에서의 실제 Physical Address는 100 + 32K가 됩니다.이 계산 방식은 Code와 Heap이 동일 합니다. 그리고 이들 가상으로 할당한 Address Space size를 넘어가게 된다면 Segmentation Fault가 발생하게 됩니다. 아래와 같은 코드로 Code와 Heap 영역의 Segment를 추론할 수 있습니다.
# get top 2 bits of 14-bits VA
Segment = (VirtualAddress & SEG_MASK) >> SEG_SHIFT
# now get offset
Offset = VirtualAddress & OFFSET_MASK
if(Offset >= Bounnds[Segment]):
RaiseException(PROTECTION_FAULT)
else:
PhyAddr = Base[Segment] + Offset
Register = AccessMemory(PhyAddr)
# SEG_MASK = 11 0000 0000 0000
# SEG_SHIFT = 12
# OFFSET_MASK = 00 1111 1111 1111
# VirtualAddress = 01 0000 0110 1000
# 00 : Code | 01 : Heap | 10 : Not Use | 11 : Stack
앞에서 우리는 Code와 Heap에 관해서만 이야기 했습니다. 그렇다면 Stack의 경우는 어떤지 이제 확인해보도록 하겠습니다. Stack의 경우는 추가적인 하드웨어 구현이 필요합니다. 왜냐하면 Stack의 방향은 앞서 언급한 것들과는 반대 방향으로 메모리가 할당되어 가기 때문입니다. 따라서 우리는 주소공간이 이동하는 방향도 설정을 해주도록 해야 합니다. 만약 Code와 Heap 영역이 1 방향이라고 가정을 하면 Stack은 0방향이라고 할 수 있습니다.
그리고 각각의 Segment는 Address Space 사이에서 공유가 될 수 있습니다.코드를 공유하는 시스템이 오늘 날의 주류 시스템입니다. 이 방법도 추가적인 하드웨어 지원이 필요 합니다. 그리고 이런 추가적인 하드웨어는 Protection Bit 기능을 지원하여 허가 받지 않은 프로세스의 접근을 막도록 합니다.
결과적으로, 이러한 Fragmentation 기법은 매우 효율적일 수 있습니다. 하지만 이 방법을 통해 Internal Fragmentation(프로세스가 필요한 양보다 더 큰 메모리가 할당됨)은 어느 정도 방지가 가능하나, External Fragmentation(총 비는 메모리 공간은 충분하나 이것이 중간중간 생기는 작은 공간이라 할당할 수 없는 경우)의 방지가 불가능한 단점을 가지고 있습니다.