출처 : Willian Stallings. (2013). Computer Organization and Architecture. London:Pearson
Input/Output
IO 장치들은 여러 문제가 있습니다. 주요 문제로는 3가지 가있습니다.
- 다양한 주변 장치의 존재
- 서로 다른 데이터를 전송을 합니다.
- 서로 다른 속도로 동작합니다.
- 서로 다른 포맷을 가집니다.
- CPU와 RAM보다 느립니다.
- 입출력 모듈을 필요로 합니다.
여기서 입출력 모듈이란 CPU와 메모리의 인터페이스(interface)이고, 하나 또는 그 이상의 주변 장치에 대한 인터페이스를 의미합니다. 보편적인 입출력 모듈의 모습은 아래와 같습니다. 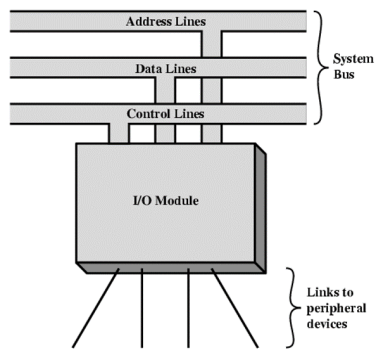
그리고 이러한 모듈의 내부 설계는 아래와 같은 논리를 가집니다.
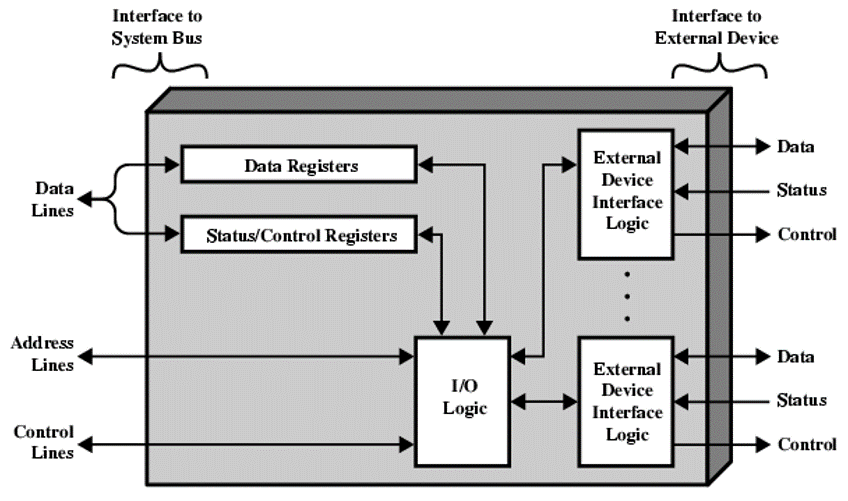
이 때, 입출력 작업은 아래의 순서에 따라 작동을 하도록 합니다.
- CPU가 입출력 모듈 장치의 상태를 확인을 합니다.
- 입출력 모듈이 상태를 반환합니다.
- 만약 준비가 되었으면 CPU가 데이터 전송을 요청합니다.
- 입출력 모듈은 장치로부터 데이터를 받도록 합ㅈ니다.
- 입출력 모듈이 cpu로 데이터를 전송을 시킵니다.
Programmed I/O
입출력 모듈 중에 프로그램 입출력(Programmed Input/Output)은 IO로부터 제어권을 CPU가 가져와서 작업을 진행을 하는 것으로 CPU는 입출력 모듈이 명령어의 수행 완료를 기다립니다. 따라서 이 방식은 CPU의 시간을 소모합니다. 이는 위의 일반적인 입출력 모듈에서 추가적인 순서가 더 들어갑니다.
- CPU가 입출력 명령을 요청합니다.
- 입출력 모듈이 명령을 수행합니다.
- 입출력 모듈이 상태 비트를 설정합니다.
- CPU는 상태 비트를 주기적으로 확인합니다.
- 입출력 모듈이 CPU에 직접적으로 알려주지는 않습니다.
- 입출력 모듈이 CPU에 인터럽트를 보내지 않습니다.
- CPU는 기다리거나 나중에 다시 오도록 합니다.
이런 입출력 모듈의 대부분이 가지고 있는 명령어는 아래와 같습니다.
| 이 름 | 하는 일 |
|---|---|
| control | 모듈이 무엇을 해야하는 지 전달합니다. |
| test | 상태를 확인하도록 합니다. |
| R/W | 장치로 부터(보내는) 버퍼를 통해 데이터를 전송합니다. |
그리고 이러한 모듈 하에서는 데이터의 전송은 CPU의 관점에서는 메모리의 접근과 비습한 방식을 취합니다. 이러한 입출력의 매핑은 크게 메모리에 하는 방법이 있고, 분리된 입출력 방식이 있습니다.
Memory mapped I/O
장치들과 메모리는 주소 공간을 공유합니다. 입출력은 메모리의 입출력과 비슷하게 동작합니다. 입출력에는 특별한 명령어를 필요로 하지 않습니다. 이들의 모형은 아래와 같습니다.
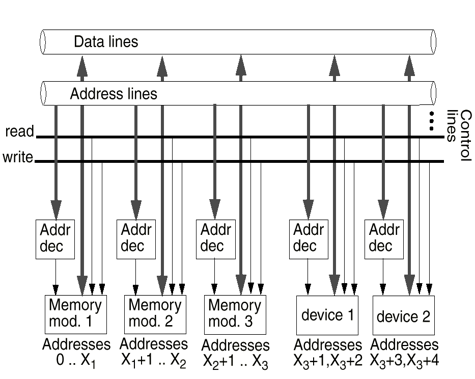
Isolated I/O
이는 분리된 주소 공간을 사용합니다. 이들은 입출력 또는 메모리 선택 줄이 필요로 합니다. 그리고 입출력 명령을 필요로 합니다. 이들의 모형은 아래와 같고, 주의해서 볼 사항으로 I/O read, write 부분입니다.
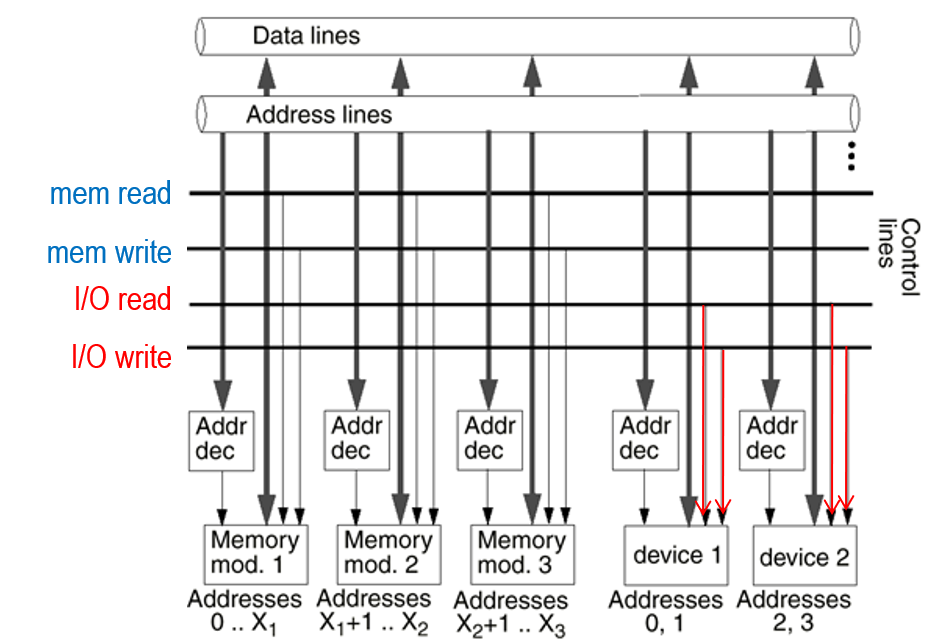
하지만 결국 이 방식은 CPU에 너무 부하가 크기 때문에 새로운 방법이 요구되게 되었습니다.
Interrupt Driven I/O
이 방식은 CPU의 대기를 극복하기위해 나온 방식으로 장치를 확인하기 위한 CPU의 반복 작업이 필요로하지 않습니다. 입출력 모듈은 준비가 되면 인터럽트를 보내도록 합니다. 이것은 아래와 같은 알고리즘 하에서 동작을 하게되며, 인터럽트를 발생 시키는 주체는 입출력 모듈이고 처리하는 것은 CPU가 됩니다.
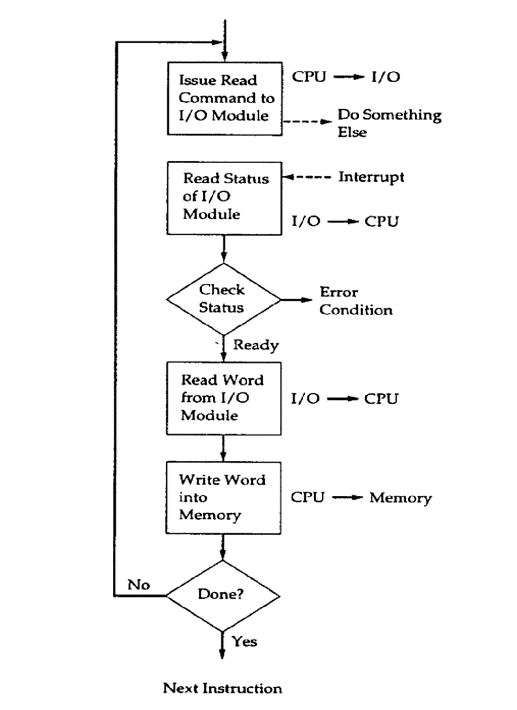
입출력 모듈의 관점에서는 아래와 같이 동작을 합니다.
- 읽기 명령을 받도록 합니다.
- 데이터를 연관된 주변 장치로부터 읽어오도록 합니다.
- 데이터가 준비가 되었을 때, 프로세서에 인터럽트 신호를 보내도록 합니다.
- 프로세서로부터 데이터 요청이 들어올 때까지 기다립니다.
CPU의 관점에서는 아래와 같이 동작을 합니다.
- 읽기 명령을 보내도록 합니다.
- 다른 일을 합니다.
- 각 명령어의 주기의 끝에 인터럽트를 확인을 하도록 합니다.
- 만약 인터럽트가 있으면 연태 문맥(context)을 저장1을 하고 인터럽트를 수행합니다.
Interrupt Processing
인터럽트가 어떻게 동작하는 지 확인을 해보도록 하겠습니다. 먼저 어떤 임의의 위치 N에서 인터럽트가 발생한 경우를 확인을 해보도록 하겠습니다.
- 인터럽트가 사용자의 프로그램 N 위치에서 실행이 될 때 발생을 하였습니다.
- PC(N + 1)의 내용과 보편적인 레지스터들(General Registers)을 스택에 저장하도록 합니다.(저장 위치 : T - M)
- 이 때, 스택 포인터는 “T - M”으로 갱신됩니다.
- PC가 “Y”로 갱신되게 됩니다.
- 인터럽트 서비스 루틴을 실행하도록 합니다.
전반적인 작업 모형은 다음과 같습니다.
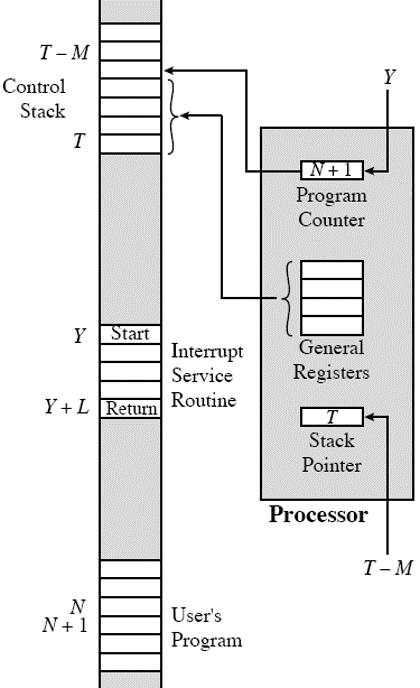
그리고 인터럽트에서 빠져나올 때는 다음과 같은 작업이 수행됩니다.
- 인터럽트 서비스 루틴이 완료됩니다.
- 저장된 PC와 보편적인 레지스터들을 복구하도록 합니다.
- 스택 포인터를 “T”로 설정합니다.
- 이제 사용자 프로그램을 실행하도록 합니다.
그렇다면 이러한 인터럽트 모듈을 구별하는 방법은 어떤 것을 사용해야 하는 지 알아보겠습니다. 크게 소프트웨어적인 방법과 하드웨어적인 방법으로 나뉩니다.
| 방 법 | 내 용 |
|---|---|
| 소프트웨어 | - CPU가 각각의 모듈이 본인의 차례가 되었는 지 묻는 방법입니다. - 속도가 느립니다. |
| 하드웨어 | - IACK2가 체인을 통해 전송됩니다. - 체인화된 버스에서 본인의 벡터에 해당하는 위치에 대해 모듈은 책임을 가집니다. - CPU는 받은 벡터 값을 바탕으로 핸들러 루틴(handler routine)을 구별해야 합니다. - 그림의 최좌측의 BPRN3은 버스에 높은 우선순위를 가진 에이전트가 없음을 가리킵니다. - 만약 에이전트가 버스를 필요로 하지 않으면 BPRO4가 발생합니다. |
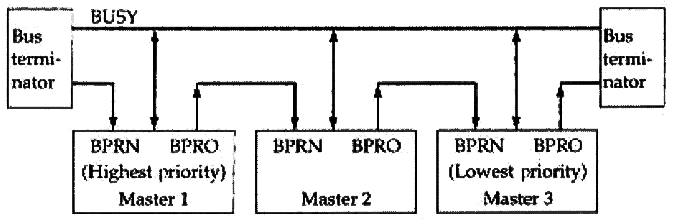
여기서 하드웨어적인 방법은 Daisy Chain이라고도 합니다. 그리고 하드웨어적인 BPRN, BPRO 작업은 한 클럭 내에서 발생하며 구현이 절대 쉬운 작업은 아닙니다.
그렇다하여 모든 방식이 Daisy Chain을 따르지는 않습니다. 이를 테면, Daisy Chain 방식이 아닌 것을 사용하는 대표적인 인터럽트 제어 모듈로는 82C59A 인터럽트 제어기가 있습니다. 이것은 ISA(Instruction Set Architecture) 버스 인터럽트 시스템으로 버스 마스터 방식입니다. 이 방식은 아래와 같은 모형으로 장치 1, 7에서 인터럽트가 동시에 발생을 하면 값이 버스 마스터 컨트롤의 1에서 인터럽트가 나오게 됩니다. 이것의 우선 순위는 0이 가장 크고, 숫자가 커질 수록 작아지는 방식입니다.
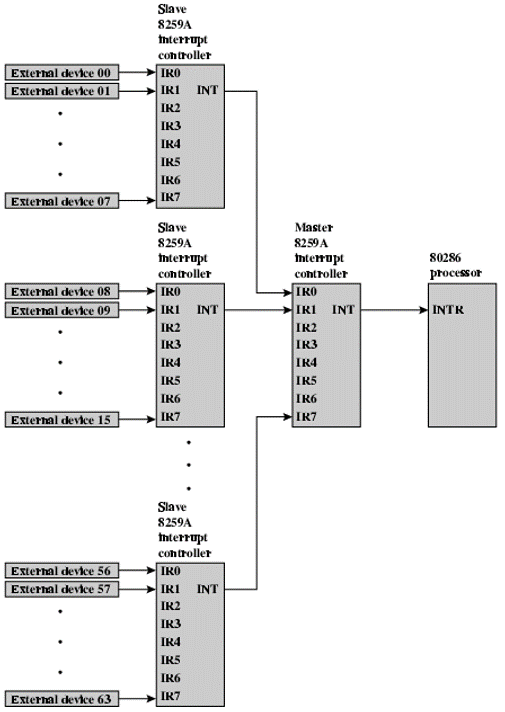
하지만 이 방식에도 결점이 있는 것이 결국은 프로그램 입출력과 동일하게 CPU의 간섭이 필요하다는 점이 있습니다. 이는 곧 전송 비율이 제한이 되게 된다는 것입니다. 따라서 블럭 단위의 전송에는 비효율적일 수 밖에 없습니다. 이를 해결하기 위해 많은 양의 데이터를 옮기는 방식이 등장하게 되었습니다.
Direct Memory Access(DMA)
DMA는 아래와 같은 절차에 따라 동작하도록 합니다.
- CPU가 DMA 제어기에 이야기하도록 합니다.
- R/W
- 장치 주소
- 메모리의 주소 정보
- 얼마의 데이터를 보낼 것인지
- CPU는 다른 작업을 할 수 있습니다.
- DMA 제어기는 전송을 다룹니다.
- DMA 제어기는 종료가 되면 인터럽트를 보내도록 합니다.
이러한 DMA의 보편적인 작동 모델은 아래의 모델을 따릅니다.
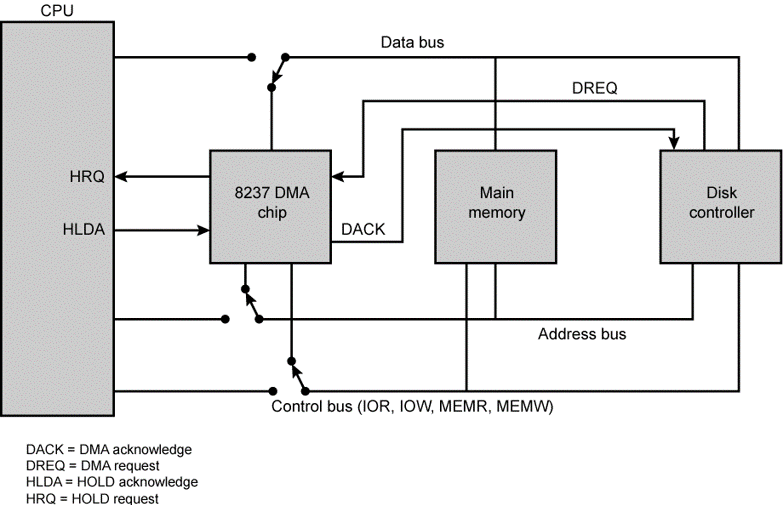
여기서 각각의 것에 관해서 이야기하면 HRQ는 버스를 DMA가 잡아도 되는 지 묻는 명령입니다. HLDA는 버스를 사용해도 문제없음을 이야기 합니다. 그리고 DACK는 DMA가 사용가능 해졌음을 이야기하는 것입니다. DREQ는 DMA에 접근하고 싶다는 것을 이야기하는 것입니다. 이러한 DMA 칩은 CPU처럼 데이터를 하나하나 처리하는 것이 아니라 특정 메모리 블럭으로 처리를 하도록 합니다.
이러한 모델은 DMA 제어기를 저쳐야 하는 초창기 방식입니다. 요즘의 경우 이를 거치지 않고 메인 메모리와 디스크 제어기 사이에서 할 것 다해버립니다. 이를 Fly-By라고 합니다. 여기서 DMA가 하는 역할은 입출력 포트와 메모리 사이의 중간 경로 역할 밖에 하지 않습니다.