지난 시간 내용 복습
저번 시간에 총 3가지 내용을 배웠습니다. 첫 번째로는 언어 구현 방법에 관해서 배웠습니다. 컴파일러는 원시 프로그램을 받고 목표 프로그램을 생성합니다. 인터프리터는 원시 프로그램을 받아 그것을 실행을 합니다. 혼합형의 경우는 컴파일러와 인터프리터 사양을 전부 다 채용하고 있습니다.
그리고 두 번째로는 분석-통합 모델에 관해서 배웠습니다. 많은 소프트웨어가 이 방식을 채택함을 알 수 있었기에 충분히 이를 확인할 필요가 있다는 것을 알았습니다. 이러한 분석-통합 모델은 아래의 절차에 따라서 진행이 되게 됩니다.
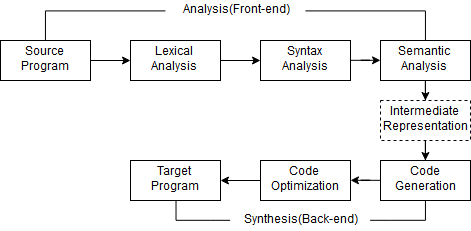
여기서 각 과정을 간략하게 살펴보면 아래와 같이 정리 가능합니다.
Lexical Analysis
E = m * c ** 2에 대해서 단어(토큰, 어휘 항목1)로 자르도록 합니다. 그 결과 아래와 같이 자를 수 있습니다.
(ID, "E")
(ASSIGN_OP)
(ID, "M")
(MUL_OP)
(ID, "C")
(POW_OP)
(INT, 2)
Syntax Analysis
문맥 분석은 아래와 같은 파스 트리(Parse Tree)라고 추후 배울 내용의 것을 만들도록 합니다.
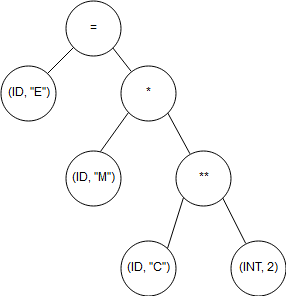
Semantic Analysis
전 단계까지는 단어만 분리되었다면 이 단계에서는 실질적으로 형에 관해서 분석하고 실질적으로 컴퓨터에서 연산 가능한 내용으로 변환이 되게 됩니다. 분석 전에 ID는 실수형(float) 데이터가 들어있다고 가정하겠습니다. 이에 따라서 새롭게 만들어지는 파스 트리는 아래와 같이 됩니다. 여기서 i2f는 integer to float를 의미합니다.
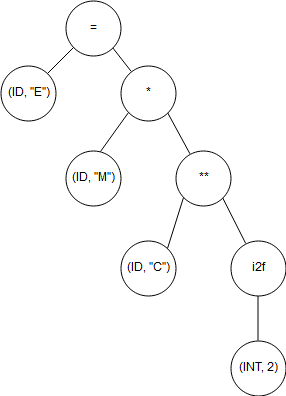
Intermediate Representation
여기까지 완성하면 중간 표현(Intermediate Representation)이 나타나게 됩니다. 이런 중간 표현을 거쳐서 기계에 맞는 코드로 변경이 되게 됩니다.
float t1 = (float)(2);
float t2 = pow(ID_C, t1);
float t3 = ID_M * t2;
ID_E = t3;
그리고 이 표현도 최소 단위로 최적화가 발생하게 됩니다.
float t1 = pow(ID_C, 2.0);
float ID_E = ID_M * t1;
Code Generation
이렇게 만들어진 중간 표현을 바탕으로 기계가 해석할 수 있는 언어로 변경이 되게 됩니다.
Code Optimization
변경 후에 빠르고 압축된 소스 코드를 만들기 위해서 무한한 임시 변수를 유한한 레지스터에 할당이 될 수 있도록 변환하고, 연산을 좀 더 빠른 명령을 선택하도록 합니다.
이 모든 과정을 지나게 되면 목표 프로그램이 만들어지게 됩니다. 여기서 가장 중요한 것은 중간 표현입니다. 이를테면, n개의 분석 과정에 m개의 통합 과정이 있는 경우 중간 표현이 없는 경우는 \(n \times m\)개의 컴파일러를 만들어야 하지만 중간 표현이 있게 되면 \(n+m\)개의 컴파일러만 만들면 됩니다.
마지막으로는 단계(phase)와 패스(pass)에 관해서 배웠습니다. 단계는 프로그램 변화의 과정을 이야기하는 것이고, 패스는 전체 프로그램을 스캔(scan)하는 것이었습니다.
오늘은 언어 문제와 런타임 시스템을 배워보도록 하겠습니다.
언어 문제
일반적인 언어들의 출력문을 보도록 하겠습니다.
- C:
printf("Hello\n"); - C++:
cout << "Hello" << endl; - Java:
System.out.println("Hello"); - Python:
print("Hello")
이것들의 차이를 보면 먼저 절차 지향이냐 객체 지향이냐에 따라서 패러다임이 다른 것을 알 수 있습니다. 그리고 개행(new line)을 하는 방식도 다른 것을 알 수 있습니다.
그렇다면 이렇게 언어들이 패러다임이 다른 것을 알 수 있습니다. 좀 더 나아가서 언어들의 형(Type)과 선언(Declaration)은 또 어떻게 다른지 알아보도록 하겠습니다.
형(Type)
사실 형이라는 것은 명시적으로든 묵시적으로든 존재해야 합니다. 하지만 형이 명시적이냐 묵시적이냐에 따라서 형에 의존하는 언어와 그렇지 않은 언어로 나뉩니다. 전자에 해당하는 언어들은 모든 값 또는 표현은 형을 가지게 됩니다. 대부분 형에 의존하는 언어는 식별자(identifiers)에 의한 선언이 있어야 하며, 그 형은 실행과정에서 변경이 될 수가 없습니다. 예를 들어, C/C++, Java, Pascal, Scala, Haskell, ML 언어가 존재합니다.
후자에 해당하는 언어들은 식별자와 형 간에 느슨한 결합(loose coupling)으로 되어있습니다. 그래서 형에 의존하지 않는 것처럼 보입니다. 예를 들어, Python, JavaScript, LISP, Scheme 등이 있습니다.
선언(Declaration)
대부분 형에 의존하는 프로그래밍 언어는 그들의 식별자를 위해서 사용하기 전에 선언하게 되어있습니다. 이 방법은 형 확인(type checking)에 유용하며 이 방식을 이용하면 단일 패스(one-pass) 컴파일을 가능하게 만들어줍니다.
그리고 모든 언어는 형 안정성(type-safety)2을 위해 형 확인을 시행하도록 합니다. 이러한 형 확인을 하는 그것 중에서 모든 형 오류를 검출하는 언어를 보고 강한 형(strong-typed) 언어라고 합니다.
그런데 용어 중에 강한 형이 있고, 정적 형(static typing)이 있습니다. 이 둘은 서로 다른 개념입니다. 강한 형은 언어 속성의 일종으로 언어가 강한 형이라는 것은 모든 형 오류를 검출 할 수 있으며, 이러한 검출의 시간은 컴파일 또는 런타임에 진행 할 수 있습니다. 하지만 정적 형은 구현(implementation) 속성의 일종으로 정적 형은 컴파일 시간 동안 형 오류를 검출하도록 합니다. 그러나 사람들이 언어 \(L\)이 정적으로 지정된 형인(statically typed) 언어라고 이야기하는 것은 언어 \(L\)의 일반적인 구현이 정적 형을 지원함을 말합니다.
프로그래밍 패러다임
프로그래밍 패러다임은 프로그래밍 스타일과 계산 모델의 구현(implication of computation models)에 대한 것입니다. 대부분의 프로그래밍 언어는 잘 알려진 프로그래밍 패러다임을 지원합니다. 이런 잘 알려진 프로그래밍 패러다임으로 아래와 같이 있습니다.
- 명령형(imperative) 언어: 프로그램은 일련의 명령(instruction)으로 구성됩니다.
- 절차형(procedural) 언어: 프로그램은 절차의 집합으로 구성됩니다.
- 함수형(functional) 언어: 프로그램은 함수로 구성됩니다.
- 논리형(logical) 언어: 프로그램은 논리 절(clause)들로 구성됩니다.
- 객체 지향(object-oriented) 언어: 프로그램은 객체(object)들의 집합으로 구성됩니다.
런타임 시스템(Run-Time System)
런타임 시스템은 실행 파일(컴파일된 코드)이 실행되는 시스템을 의미합니다. 대부분의 런타임 시스템은 서브프로그램(subprogram)을 위한 제어 스택(control stack)을 지원합니다. 그리고 런타임 시스템은 힙(heap)이라는 객체를 수동으로 자유롭게 할당시켜 저장 가능한 공간을 지원합니다.
그리고 몇몇 언어는 쓰레기 수집(garbage collector)이라 불리는 자동 메모리 관리 방법을 지원합니다. 이는 사용되지 않는 메모리 공간(dead memory cells)의 반환을 시스템에 요청하는 하위시스템(subsystem)입니다. 대부분의 가상 머신 기반으로 구현된 것들을 쓰레기 수집을 지원합니다.
스택 머신(Stack Machine)
추상 스택 머신(abstract stack machine)이라고 있습니다. 이는 임시 변수를 스택에 할당하는 간단한 기계입니다. 그리고 기계가 제공하는 레지스터를 활용해서 최적화된 동작을 만들기 위해 레지스터에 스택 상단에 있는 부분의 값을 레지스터에 할당을 해주도록 합니다.
예를 들어, 스택 머신에 들어오기 전에 어떤 표현 식(\(1+2\times3\))이 들어와서 분석되었다고 하겠습니다. 이 분석 결과 소스 코드가 아래와 같이 만들어집니다.
push 1
push 2
push 3
mul
add
여기서 연산이 일어나는 부분은 mul과 add 부분입니다. mul에서 먼저 일전에 스택 머신에 넣은 \(3, 2\) 값을 레지스터로 가져와서 이 둘을 곱한 후에 결괏값을 레지스터에 넣습니다. 그리고 add에서 레지스터에 있는 결괏값에 스택 머신의 \(1\) 값을 레지스터로 가져와서 더해주도록 합니다.
Polish & Reverse-Polish
폴란드 표기법(polish)은 흔히들 이야기하는 전위 표기법(prefix)을 의미하고, 역 폴란드 표기법(reverse-polish)을 후위 표기법(postfix)이라고 합니다. 각각은 아래와 같은 방식으로 사용됩니다.
- infix: \(1+2\)
- prefix: \(+\ 1\ 2\)
- postfix: \(1\ 2\ +\)
일반적으로 스택 머신은 역 폴란드 표기법으로 제작됩니다. 위에서 예제의 과정을 수식으로 나타내면 아래와 같이 작성이 가능할 겁니다.
\[1\ 2\ 3\ *\ +\]이 반대인 폴란드 표기법은 LISP나 Scheme 같은 언어에서 사용됩니다.